Vitalik has a brilliant article about the Endgame for blockchains. I’m obviously biased, but this may be my single favourite piece of writing about blockchains this year. While Vitalik is an actual blockchain researcher (and IMO, the very best our industry has) I’m just here for shits & giggles, and I can have wild dreams. So, I thought I’d take Vitalik’s pragmatic endgame to the realm of wishful thinking. Be aware that a lot of what I say may not even be possible, may just be a mad person’s rambling, and definitely not for many years.
I’d highly recommend reading some of my earlier posts here: Rollups, data availability layers & modular blockchains: introductory meta post | by Polynya | Oct, 2021 | Medium. In this post, I’ll assume that you’re fully convinced about the modular architecture.
Decentralizing the execution layer
It’s pretty obvious that a fraud-proven (optimistic rollup) or validity-proven (ZK/validity rollup) execution layer is the optimal solution for blockchain transaction execution. You get a) high computational efficiency, b) data compression and c) VM flexibility.
Today, barring Polygon Hermez, most rollups use a single sequencer, or at least sequencers run by permissioned entities. A properly implemented rollup still gives users the opportunity to exit from the settlement layer if the rollup fails or censors, so you still inherit high security. However, this is inconvenient and could lead to temporary censorship. So, how can rollups have the highest level of censorship resistance, liveness or finality?
Today, high-throughput monolithic blockchains make a simple trade-off: have a smaller set of block producers. Likewise, rollups can do the same, but they have an incredible advantage. While monolithic blockchains have to offer censorship resistance, liveness & safety permanently, rollups only need to offer censorship resistance & liveness ephemerally! Today, this can be anywhere between 2 minutes to an hour depending on the rollup, but as activity increases, I expect this to drop to a few seconds over time. Needing only to offer CR & liveness for a few seconds has huge advantages: you can have a small fraction of block producers than even the highest-TPS monolithic blockchain, meaning you can have way higher throughput and way lower finality. But at the same time, you also have way higher CR & liveness per unit time, and you inherit security from whatever’s the most secure settlement layer! It’s the best of all worlds.
Further rollups need not use inefficient mechanisms like BFT proof-of-stake, because they have an ephemeral 1-of-N trust model: you only need one honest sequencer to be live at a given time. They can build more efficient solutions better suited to ephemeral. You can have sequencer auctions, like Polygon Hermez already has. You can have rotation mechanisms. I.e. have a large block producer set, but only require a smaller subset to be active for a given epoch, and then rotate between them. Eventually, I expect to see sequencing & proving mechanisms built around identity and reputation instead of stake. There’s a lot more to say about this topic, such as checkpoints, recursing proofs etc. But I’ll stop for now. Speaking of recursive proofs…
Rapid innovation at the execution layer
One of the greatest challenges for blockchains has been upgradability. Analogies like “it’s like upgrading a space shuttle while it’s still in flight” are apt. This has made upgrading blockchains extremely difficult and extremely slow. The more popular a blockchain is, the harder it becomes to upgrade.

With a modular architecture, the permanent fate of the rollup no longer depends on the upgradability. The settlement layer contains all relevant proofs and the latest state, while the data availability layer contains all transaction data in compressed form. In short, the full state of the rollup can be reconstructed irrespective of the rollup itself!
This frees the rollup to innovate much faster — within reason. We’ll see MEV mitigation techniques like timelocks & VDFs, censorship resistance & liveness mechanisms like described above, novel VMs & programming languages, advanced account abstraction, innovative fee models (see: Immutable X and how they can have zero gas fees), high-frequency state expiry, and much more! We could even see the revival of application-specific rollups, which are fine-tuned for a specific purpose. (Indeed, with dYdX, Immutable X, Sorare, Worldcoin, Reddit, we’re arguably already seeing this.)
Recursion & atomic composability: a single ZKP for a thousand chains
This is totally speculative, but hear me out! We’re looking far enough out into the future that I expect all/most rollups to be ZKRs. At that point, proving costs will be negligible. Just to be clear, because so many seem to misunderstand: ORs are great, and have a big role to play for the next couple of years.
Even the highest throughput rollups will have their limits. As demonstrated above, a high-throughput ZKR will necessarily be way higher throughput than the highest throughput monolithic chain. A single ZKR remains full composability over multiple DA layers. But there’s a limit to how many transactions a single “chain” can execute and prove. So, we’ll need multiple ZKRs. Now, to be very clear, it’s pretty obvious that cross-ZKR interoperability is way better than cross-L1. We have seen smart techniques like DeFi Pooling or dAMM — which even lets multiple ZKRs share liquidity!
But this is not quite perfect. So, what would it take to have full atomic composability across multiple ZKRs? Consider this: you can have 10 ZKRs that are living besides each other. All of these talk to a single “Composer ZKR”, which resolves to a single composed state with a single proof. This single proof is then verified on the settlement layer. Internally, it might be 10 different ZKRs, but to the settlement layer, it’ll all appear as a single ZKR.
You can build further ZKRs on top of each of these 10 ZKRs, and with recursive proofs, it’ll head down the tree. However, these “child ZKRs” will probably have to give up atomic composability. It may make a lot of sense for “App ZKRs” or otherwise ZKRs with lower activity though.
Of course, not all ZKRs will follow the same standard, so you can have multiple “Composer ZKR” networks. And, of course, standalone ZKRs will continue to be a thing for a vast majority of ZKR networks that are not hitting the throughput limits.
But here’s where things get exciting! So, you could have all of those “child ZKRs”, “standalone ZKRs”, “multiple ZKRs within one composable ZKR network” — all of that can be settled on a validity proven execution layer, all verified with a single ZKP — made by a thousand recursions — at the end of it all! As we know, zkEVM is on Ethereum’s roadmap, and Mina offers a potential validity proven settlement layer sooner.
So, you have millions of TPS across thousands of chains, all verified on your smartphone with a single succinct ZKP!
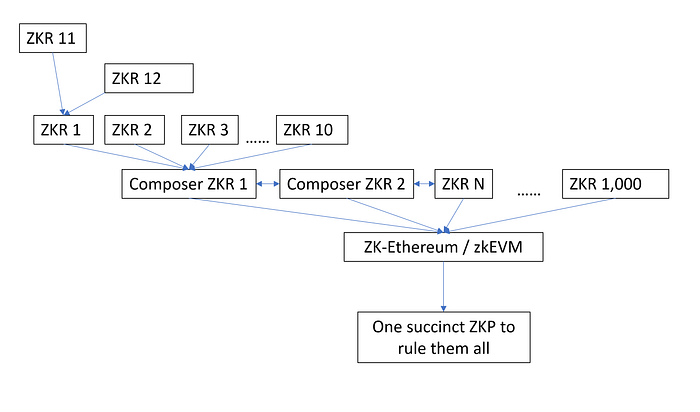
One final word: because ZKPs are either fixed or poly-log, it barely matters the number of transactions they prove. A single settlement can realistically handle thousands of ZKRs with ~infinite TPS. On Twitter, I recently calculated Ethereum today is already capable of settling over 1,000 ZKRs. So, throughput is not the bottleneck for settlement layers. They just need the most secure, the most decentralized, the most robust coordinator of liquidity and arbiter of truth.
This section is very far-fetched, to be sure! But it’s worth dreaming about. Who knows, maybe some day, the wizards at the various ZK teams will make this fantasy real.
Vibrant data availability ecosystem
The great advantage of a modular execution layer is data compression. Even basic compression techniques will lead to ~10x data efficiency. More advanced techniques or highly compressible applications like dYdX can lead to >100x gains.
But the 10x-100x gains are just the start here. The real gains come from modularizing data availability.
Unlike monolithic chains, data availability capacities increase with decentralization. With sharding and/or data availability sampling, the more validators/nodes you have, the more data you can process, effectively inverting the blockchain trilemma.
Furthermore, data availability is the easiest & cheapest resource, by several orders of magnitude. No SSDs, no high-end CPUs, GPUs etc. required. You just need cheap hard drives. You could attach a Raspberry Pi to a 16 TB hard drive: this setup will cost $400. So, what kind of scale can this system handle? Assume we set history expiry at 1 year, this is 100,000 dYdX TPS. Though, this is purely illustrative, as it’s likely we hit other bottlenecks like bandwidth too. Which, I might add, are 10x-100x lesser than monolithic blockchains due to the data compression that has already happened at the execution layer.
Expired historical data only needs a 1-of-N trust assumption, and we have multiple projects like block explorers, Portal and The Graph working on these. Still, I’d like to see the DA layers incentivize this for a bulletproof system.
Interestingly, volition type setups can also work with 1-of-N trust assumptions — so I look forward to novel, permissionless DA solutions. Here’s a fabulous post on StarkNet Shamans about how StarkNet plans to achieve this.
But it doesn’t end here, you can parallelize data availability in various ways! For example, Ethereum’s endgame is 1,024 data shards. With data availability sampling, you can go a long way before requiring sharding. Really, we’re scratching the surface here, and I haven’t even mentioned the likes of Arweave or Filecoin. I expect to see tons of innovation; in short, we have the potential for millions of TPS here, today!
Endgame
The more I learn about modular architectures, the more blatantly obvious this progression seems from monolithic blockchains. It’s not an incremental gain, it’s a >1 million x improvement over today’s L1s. It’s a bigger leap forward than going from 56k dialup straight to Gigabit fibre. Of course, it’ll take a lot of work with hundreds of cooperating teams several years to realize this vision. But as always, it remains the only way the blockchain industry will scale to global ubiquity.
PS: I still believe the path of least resistance is many rollups, few DA layers, fewest settlement layers: polynya on Twitter: “The future is multi-layered. ~1,000 execution layers (rollups, volitions, validiums) ~100 data availability layers (data sharding, decentralized committees) ~10 settlement layers (maximally secure, sustainable & decentralized) The era of monolithic blockchains (L1s) is ending.” / Twitter
